

The New Governor: Facebook’s Content Moderation

Below is a report I wrote analyzing Facebook’s content moderation. I have a strong interest in internet governance, so this exercise was an enlightening exploration of a major issue in that domain. You will find that the vast majority of “actions” taken by Facebook involve deleting spam and fake accounts. Algorithmic content moderation is not designed for or effective at managing social problems like hate speech and sexual harassment. Journalists and policy-makers would be wise to accept this reality when discussing reforms of Section 230 of the Communications Decency Act. The original version can be found on my GitHub.
Introduction
A Primer on Content Moderation
Facebook is one of the New Governors; it employs a complicated mixture of machine learning and human bureaucrats to moderate a large segment of the world’s communications system according to its Community Standards. For better or worse, because of the First Amendment, the work of curtailing objectionable content from our online information ecosystem falls to private corporations like Facebook.
Recently, this governance has become a lightning rod for political criticism. Critics from all sides of the political spectrum have excoriated Facebook for its role in spreading disinformation and hate speech and “censoring” conservatives. This dissatisfaction has emerged most concretely in debates surrounding amendments to Section 230 of the Communications Decency Act, which confers broad immunity to online intermediaries like Facebook from legal liabilities for user-generated content.
Major revisions to Section 230 would significantly change the Internet as we know it, so policymakers must study the complex realities behind Facebook’s content moderation before taking action. Luckily, as part of its quarterly Transparency Report, the company has regularly published data about its content moderation since 2017. Below I explain this data and then outline a set of questions explored here.
Explanation of Facebook Transparency Data
The data provide information about content moderation decisions made by Facebook and Instagram. Specifically, they contain metrics like number of overall “actions” (i.e. deletions), proactive actions (i.e. deletions without human flagging), appeals, and restores with and without appeal. These metrics are provided broken down by the 12 categories of content (enumerated here) prohibited according to the Community Standards. I tidied the data and broke it up into two data frames containing the same variables: one for Facebook and one for Instagram. Here I focus solely on data for Facebook’s content moderation due to the poor quality of Instagram’s data.
Questions to Explore
After an initial glimpse at the data, I have the following questions about Facebook’s content moderation:
Has Facebook’s content moderation changed in response to the recent wave of public attention paid to its practices?
If so, what types of content has the company begun to recently address?
What categories of prohibited content is Facebook able to moderate least and most successfully?
What implications do the answers to these questions have for policy debates surrounding Section 230 of the Communications Decency Act?
Response to Recent Public Pressure
Over the last few years, Facebook’s content moderation has come under increasing scrutiny everywhere from the media to electoral politics. I hypothesize that Facebook would adapt to this increased pressure by taking a more aggressive stance against categories of content viewed as particularly objectionable by the public. I start my analysis with a big picture look at the number actions Facebook has taken against unacceptable content over the last few years:
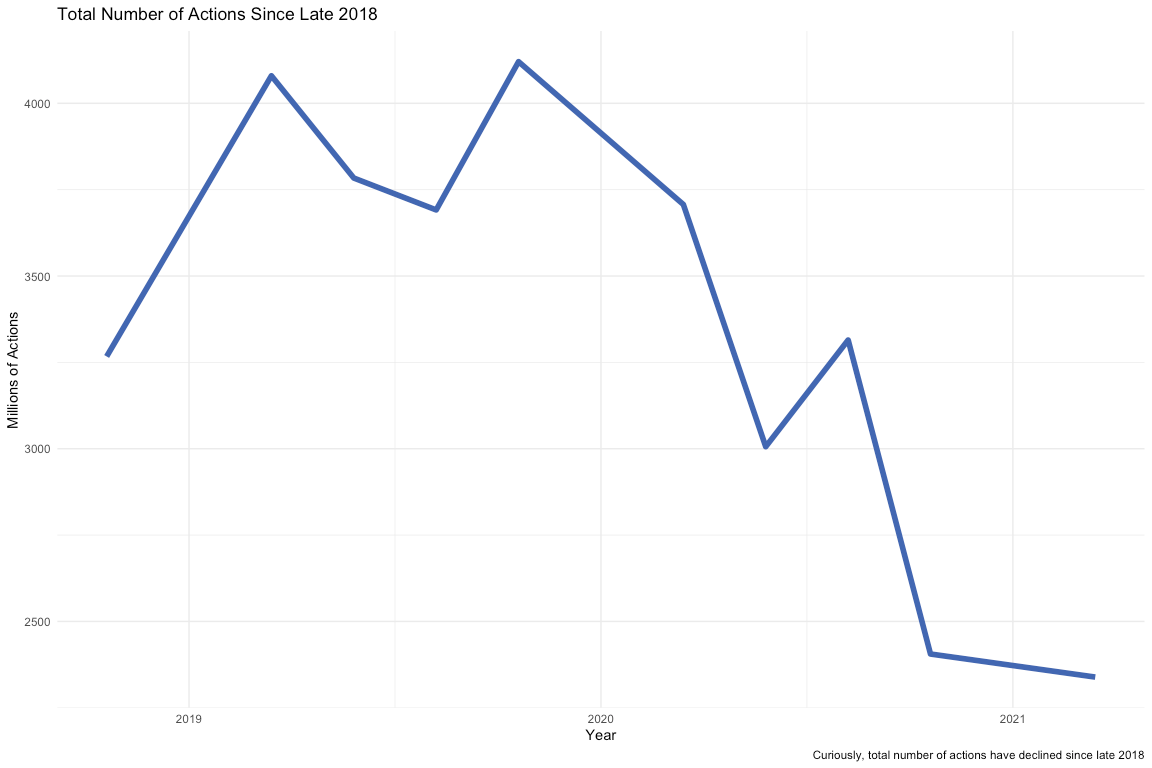
At first, this figure surprises. Facebook has taken fewer actions to moderate content since late 2018? If anything, public pressure demands more investment and care in curtailing unacceptable content from the social networking giant. What explains this seeming discrepancy? Luckily, we have more information at our disposal; we break down the total number of actions by policy area (i.e. category of restricted content).

The figure above makes clear that the vast majority of actions taken by Facebook’s content moderation system are against spam content and fake accounts. All other categories pale in comparison to the point that they barely register on the graph. Changes in the amount of spam and fake content moderated will have profound effects upon the total number of actions taken. Just to drive the magnitude of these two categories of content home, I break down the number of actions in a stacked bar graph:
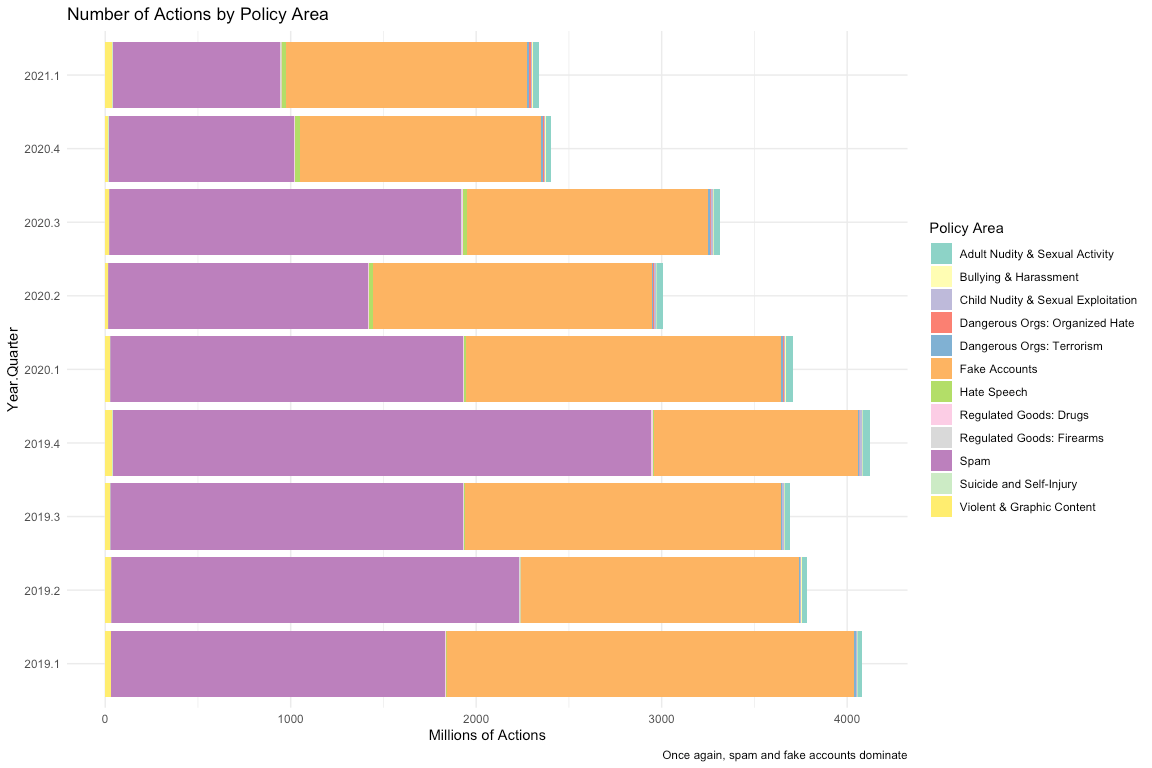
But we have yet to answer our initial question! Why are the total number of actions going down in spite of recent public attention to content moderation? It is clear from the graph above that number of actions against spam and fake accounts are decreasing, but what about the other categories? Perhaps their changes are more in line with our hypothesis of greater aggressiveness in content moderation. Let us find out.

Once spam and fake accounts have been removed from the plot, it becomes clear that the overall decrease is almost entirely explained by their diminution. The other policy areas while smaller show no clear downward trajectory. Three categories stand out in this plot for their magnitude: Violent & Graphic Content, Adult Nudity & Sexual Activity, and Hate Speech.
The latter is particularly interesting as its increase during 2020 might reflect greater attention by Facebook to addressing criticisms related to hate speech on its platform. While it is possible that this increase is due to background events, the jump in number of actions is sudden enough that Facebook could have started more actively curtailing it in response to public pressure. Here we have a confirmatory indicator for our hypothesis.
The Limits of Content Moderation
Like any other computational tool, the machine learning elements of Facebook’s content moderation are imperfect. It is known that machine learning algorithms struggle to understand a content’s context to the same degree a typical human can. Some categories of content, then, simply defy easy classification for machines. Therefore, I hypothesize that categories of content which require strong reference to their context are more error prone than categories that are easier to define in a stricter sense.
I test this hypothesis by comparing the proactive rate and percent of actions appeals across each category of content. Context-dependent categories like Hate Speech and Bullying & Harassment will be less efficacious than more objectively definable categories like Spam and Child Nudity & Sexual Exploitation. That is, context-dependent categories will have lower proactive rates and higher percentages of appeal relative to more objective categories.
The above graph is in line with the hypothesis. The proactive rate measures the percentage of actioned content removed prior to any human flags, i.e. detected by machines without human assistance. It is thus a measure of the efficacy of machine learning algorithms for each content category. The box plots show the central tendency and distribution of this rate by policy area. One can see that the context dependent groups are both systematically lower and more variable than the more objective.
In particular, detection of Bullying & Harassment is startlingly low and Hate Speech unacceptably variable. In the box plot without these two categories, it is easy to see that every other category possesses proactive rates in excess of 90%, especially Spam and the most objective categories like Child Nudity & Sexual Exploitation which are near perfect. Machine learning algorithms are thus limited in their capacity to deal with context-dependent content, a weakness that ensures some user exposure.
If artificial intelligence is less likely to correctly flag context-dependent content, what about when it does assert a classification? Will it be prone to making disproportionate errors? I check this below by comparing the percentage of appeals across policy areas.

Indeed, the hypothesis’s prediction once again proves accurate. The percentage of actions against context-dependent content, particularly Hate Speech and Bullying & Harassment, is much higher and more variable than the their more objective counterparts. Interestingly, content removed for Adult Nudity & Sexual Activity also appears prone to appeal. Spam content and Child Nudity & Sexual Exploitation by comparison rarely see appeals. Once more the data exposes the errors made by machine learning algorithms when they flag context-dependent content.
Conclusion
We conclude by answering my last question. It has become clear from the analysis above that there are real issues with Facebook’s content moderation system as well the public’s understanding of it. Firstly, while the public focuses on issues like disinformation and hate speech, Facebook’s content moderation is not geared toward nor effective at resolving these issues. In spite of a recent increase in the number of actions against Hate Speech, moderation the vast majority of the time removes less controversial content like spam and fake accounts.
And when the machine learning elements of content moderation do focus on more objectionable content, they are often ineffective. From hate speech to disinformation this content is usually only identifiable by referencing context, which is a challenging task for today’s machine learning algorithms. Advocates of reform to Section 230 must have these hard realities in mind. The fundamental limits of technology make incentivizing more aggressive moderation by exposing technology companies to liabilities for user-generated content a blunt tool to address the blight of objectionable content.